
GTX 970: 3.5 Go et 224-bit au lieu de 4 Go et 256-bit ?



Cela s'agite depuis quelques jours dans les forums spécialisés : la GeForce GTX 970 serait affectée par un problème au niveau de sa gestion de l'allocation mémoire. Bien qu'équipée de 4 Go, le pilote fait en effet en sorte de se contenter autant que possible de ne pas dépasser 3.5 Go et les performances chutent dans des tests synthétiques spécifiquement dirigés pour forcer l'exploitation d'une quantité de mémoire plus élevée. Bug ? Tromperie sur la marchandise ? Nous avons pu obtenir des éclaircissements de la part de Nvidia en début de semaine, l'occasion d'une première publication de ce focus qui est mis à jour en cette fin de semaine avec les derniers éléments en notre possession.
Nvidia a communiqué des spécifications erronées
Que ce soit par erreur, par omission ou volontairement - nous ne pouvons pas le savoir avec certitude - Nvidia nous a au départ communiqué des spécifications erronées pour la GeForce GTX 970. Des spécifications erronées qui se sont retrouvée dans notre dossier consacré à cette carte graphique et à sa grande sœur. Nvidia insiste sur le fait qu'il s'agit d'une erreur, son service de communication technique ayant présumé que l'organisation du sous-système mémoire fonctionnait sur Maxwell comme sur ses architectures précédentes. Ce n'est pas le cas et Nvidia nous explique aujourd'hui qu'au lieu de 64 unités ROP comme annoncés, une GTX 970 n'en a en fait que 56, ce qui a des implications indirectes relativement complexes.
Rappelons tout d'abord qu'il est normal de commercialiser des puces dont une partie des blocs fonctionnels ont été désactivés, que ce soit pour des raisons de segmentation ou de rendement de production. Lorsque les puces sont produites, certaines présentent de petits défauts qui peuvent dans certains cas être contournés en prévoyant de la redondance. C'est typiquement le cas pour les blocs de mémoire qui sont un petit peu plus gros que nécessaires. Dans d'autres cas une mesure plus radicale doit être prise : désactiver la zone qui souffre d'un défaut pour garder une puce partiellement fonctionnelle, aux spécifications alors revues à la baisse.
Avec les architectures précédentes, le cache L2, les ROP (unités chargées de gérer les écritures de pixels en mémoire) et les contrôleurs mémoires étaient liés de manière très rigide. Par exemple si Nvidia décidait de désactiver des ROP sur sa puce pour augmenter le rendement de la production, cela réduisait automatiquement, et dans la même proportion, la taille du cache L2 et du bus mémoire.
Avec Maxwell, les ROP et le cache L2 restent liés mais le contrôleur mémoire et son interface ont été découplés. De quoi offrir plus de flexibilité au niveau de la configuration des GPU. Le GM204, puce dont il est question ici, embarque physiquement un bus mémoire 256-bit, un cache L2 de 2 Mo et 64 ROP. Dans sa version GTX 970, et contrairement à ce qui avait été annoncé au départ, il se contente par contre d'un cache L2 de 1.75 Mo et de 56 ROP, tout en conservant un bus 256-bit pour interfacer 4 Go de mémoire GDDR5.
Avant de rentrer dans plus de détails, regardons ce que cela représente en image :
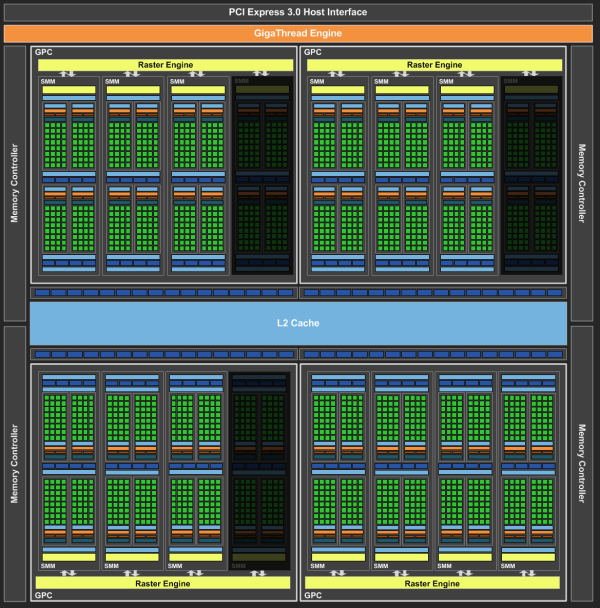
[ Le GPU de la GTX 970 tel qu'annoncé... ] [ et la réalité ]
En pratique, 1.75 Mo de cache L2 au lieu de 2 Mo ne fait pas de grosse différence et les ROP manquants sont peu utiles. Comme nous l'expliquions au lancement, le débit de pixels est en fait dépendant du nombre de SMM (les blocs d'unités de calcul). Chaque SMM peut débiter jusqu'à 4 pixels par cycle, soit 52 au total pour une GTX 970 équipées de 13 SMM. Qu'il y ait 64 ou 56 ROP, le débit de pixel est en pratique le même. Par contre les ROP supplémentaires peuvent par exemple aider à maintenir un bon rendement avec le MSAA.
Si une part importante de la production ne présente pas un ensemble L2 et ROP totalement fonctionnel, désactiver une partition de ROP n'est clairement pas insensé quand le nombre de SMM est réduit. Même si il n'y a aucun rapport direct entre les deux, disposer d'une capacité bien plus élevée au niveau des ROP que ce que ne peuvent fournir les SMM présente une utilité réduite. Avec Maxwell, pouvoir ne désactiver que les ROP et le L2 permet de moins brider le GPU et surtout de pouvoir conserver un bus mémoire complet de 256-bit avec sa mémoire vidéo de 4 Go, deux spécifications qui simplifient la vie des commerciaux de Nvidia.
3.5 Go + 512 Mo
Mais pourquoi cela pose-t-il problème au niveau de l'allocation de la mémoire ? Pour l'expliquer, Nvidia a organisé une discussion à ce sujet avec Jonah Alben, Senior Vice President GPU Architecture, et nous a fourni un schéma plus clair que nous avons édité pour former les autres déclinaisons du GM204 :
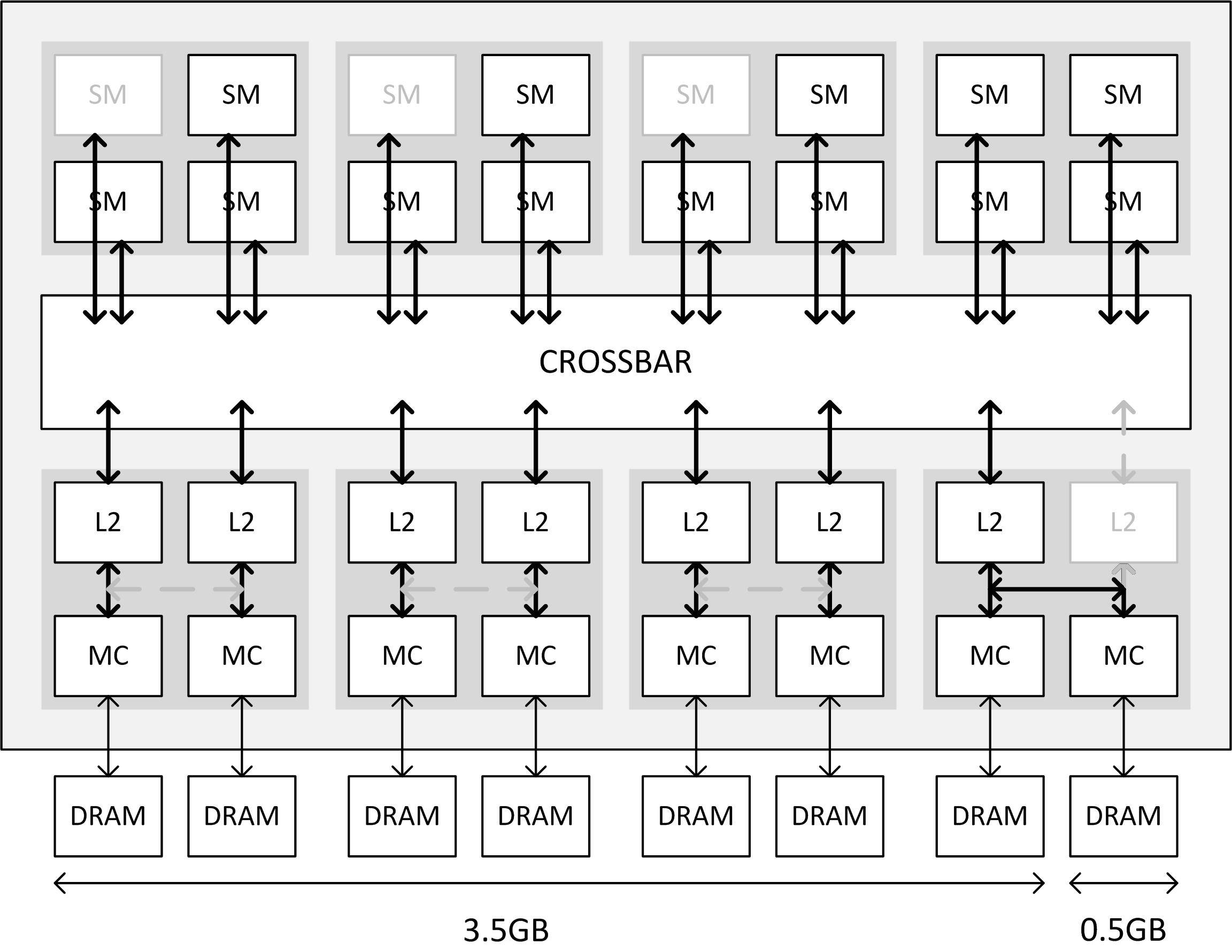
[ GTX 970 ] [ GTX 980 ] [ GTX 980M ] [ GTX 970M ]
Quand un cache L2 est désactivé, c'est également l'accès du crossbar vers un contrôleur mémoire qui disparaît. Pour pouvoir exploiter celui-ci et ne pas réduire la taille du bus mémoire, Nvidia a prévu dans son architecture un lien par paire de contrôleurs qui permet de rediriger le trafic vers le cache L2 de l'autre et ainsi de connecter deux contrôleurs au reste du GPU via un accès partagé.
Le problème c'est que cela revient à doubler la charge sur ce cache L2 et ses datapaths. Les données sont en général réparties uniformément à travers l'interface mémoire et si une partie de celle-ci est plus lente, forcément elle peut représenter un goulet d'étranglement et limiter les performances. Pour éviter de se retrouver dans cette situation, Nvidia fait en sorte de n'utiliser qu'en dernier recours le dernier contrôleur mémoire et la tranche de 512 Mo qu'il interface.
Cela signifie que Nvidia segmente sa mémoire en deux zones : une principale de 3.5 Go, connectée au GPU de manière classique, et une secondaire de 512 Mo. Le pilote et l'OS font en sorte autant que possible de ne répartir les données que dans la zone de 3.5 Go pour rester dans une situation optimale. C'est pour cela que certains utilisateurs peuvent avoir l'impression que l'utilisation mémoire ne dépasse jamais 3.5 Go, mais il n'y a pas de barrière totalement figée à ce niveau.
En fait tout dépend des conditions. Si 3.5 Go sont occupés mais que certaines données restées en mémoire n'ont plus d'utilité, par exemple des textures d'une scène précédente, le pilote va les effacer et ainsi faire de la place dans la zone de mémoire principale. Sur une GeForce GTX 980, le pilote aurait conservé ces données tant que les 4 Go n'étaient pas remplis.
Par contre, dans certains cas, plus de 3.5 Go sont réellement nécessaires ou le pilote n'a pas pu détecter de données inutiles. Le bloc de 512 Mo supplémentaires entre alors en action. Suivant la manière de répartir les données, il y a deux possibilités :
- 3 Go de mémoire rapide et de 1 Go de mémoire lente accessible en parallèle
- 3.5 Go de mémoire rapide et de 512 Mo de mémoire lente non-accessible en parallèle
C'est cette seconde option qui semble avoir été retenue, plus simple et naturelle à exploiter par rapport à l'architecture du GPU. Elle implique que quand un accès doit se faire dans la zone de 3.5 Go, il profite d'un bus 224-bit alors que quand il se fait dans les derniers 512 Mo, il doit se contenter de 32-bit ce qui est 7x plus lent.
Pour ces situations, Nvidia a mis en place des mécanismes pour tenter de placer en priorité les données les plus sensibles pour les performances dans la partie rapide de la mémoire. Si nécessaire, des optimisations spécifiques peuvent être ajoutées pour certains jeux et certaines résolutions, comme c'est déjà le cas pour de nombreuses autres raisons. Nvidia nous indique le faire pour les situations qui correspondent à un niveau de performances jouables, mais sans préciser si cela est vrai également pour les systèmes SLI, 3-way et 4-way.
Nvidia a déjà de l'expérience à ce niveau puisque c'est très proche, voire identique à ce qui a été fait pour les cartes graphiques équipées d'une configuration mémoire asymétrique. Pour rappel, les GeForce GTX 550 Ti ou GTX 660, par exemple, présentent une quantité de mémoire différente sur l'un de leurs contrôleurs. La GTX 660 est organisée de la sorte :
- contrôleur mémoire 64-bit 0 : 2x 256 Mo
- contrôleur mémoire 64-bit 1 : 2x 256 Mo
- contrôleur mémoire 64-bit 2 : 2x 512 Mo
Sur cette carte graphique, cela signifie que 1.5 Go sont accessibles à travers le bus complet de 192-bit et que 512 Mo ne sont accessibles que via un canal de 64-bit. Une opération réalisée en externe et qui permet d'afficher une quantité de mémoire de 2 Go avec un bus 192-bit. Le GTX 970 fait de même mais en interne.

[ Avant ] [ Arrière ]
Cette problématique implique donc que dans des situations classiques, la GeForce GTX 970 se comporte comme une carte graphique purement 224-bit et non comme un modèle 256-bit. Même s'il est présent physiquement en externe, il ne l'est pas réellement en interne. Cela veut dire que sa bande passante mémoire est réduite de 12.5% par rapport à une GeForce GTX 980.
Elle reste par contre une carte graphique équipée de 4 Go. Nvidia a raison de dire que mieux vaut cette configuration particulière qu'une GTX 970 qui aurait été équipée de seulement 3.5 Go. 512 Mo de mémoire graphique lente reste préférable à devoir passer par le bus PCI Express pour aller puiser dans la mémoire centrale, même si il est très probable que la raison qui se cache derrière ce choix soit avant tout marketing, une carte avec 4 Go étant plus attrayante qu’une avec 3.5 Go, surtout pour le grand public.
Par ailleurs, les voies de communication entre les contrôleurs mémoire et les partitions de L2 puis ensuite entre ces dernières et le crossbar ont été surdimensionnées pour assurer un trafic aussi fluide que possible. Dans certains cas, un seul cache L2 et son lien vers le crossbar sont capables d'encaisser une partie du trafic supplémentaire lié au pilotage de 2 contrôleurs mémoire, grâce à leur capacité totale qui serait de 2 requêtes en lectures + 2 requêtes en écritures par cycle. Il y a des limitations, par exemple tous les types d'accès ne peuvent se faire simultanément. Le seul moyen de combiner la bande passante des 2 zones, pour obtenir celle d'un vrai bus de 256-bit serait d'exécuter une lecture dans l'une et une écriture dans l'autre.
Au final, Nvidia assure ainsi que la partie lente de la mémoire ne ralenti pas le GPU autant que nous pourrions le penser. Mais il faut garder en tête que si Nvidia n'exploite la mémoire de 0.5 Go qu'en dernier recours, c'est bien parce que Nvidia estime qu'utiliser celle-ci va induire une bande passante moyenne en pratique inférieure à celle d'un bus 224-bit. Il est dès lors logique selon nous de voir la GTX 970 comme une carte graphique dont la bande passante mémoire correspond à un bus 224-bit et non 256-bit.
A noter que les GeForce GTX 980M et 970M ne sont pas affectées par ce problème. Les GTX 980M disposent d'un GPU équipé de la totalité de ses ROP et de son cache L2 et donc d'un bus 256-bit classique. Les GTX 970M sont, elles, associées à un bus mémoire 192-bit avec 48 ROP et 1.5 Mo de L2, la proportion reste donc optimale.
Et en pratique ?

Ces derniers jours nous avons essayé de trouver des cas pratiques en jeu mettant en avant une différence de comportement en défaveur de l'organisation de la mémoire sur la GTX 970 par rapport à celle sur la GTX 980, essais que nous vous avons rapportés au fil de l'eau en commentaires, nous vous invitons à vous y reporter pour les détails. Il est en effet difficile de séparer le bon grain de l'ivraie parmi les nombreux commentaires utilisateurs, qu'ils aillent dans un sens ou dans l'autre.
Nous avons entre autres essayé des jeux tels que Dying Light, Assassin's Creed : Unity, Far Cry 4, Ryse : Son Of Rome avec divers réglages permettant d'aller au-delà 3.5 Go de VRAM alloués sur la GTX 970, ou encore Watch Dogs avec un réglage allouant 4 Go de VRAM sur la GTX 980 et 3.5 Go sur la GTX 970, mais nous n'avons tout simplement pas pu mettre en avant de différences significatives et reproductibles dans des réglages offrant une jouabilité suffisante avec 1 et même 2 GPU. Quand nous avions des saccades sur 970, la 980 n’était pour autant pas complètement ou systématiquement épargnée.
C’est initialement sous Far Cry 4 nous avons rencontré une configuration avec un écart entre 970 et 980 le plus significatif (2880*1620 via 1920*1080 DSR 2.25x, Medium + Texture Ultra + MSAA 8x), mais il s'agit d'un cas pour lequel le besoin en mémoire vidéo était supérieur à 4 Go. Que ce soit sur GTX 980 ou GTX 970 les chiffres étaient très variables entre chaque essai, l'usage du bus PCIe, lié à l'usage de l'espace mémoire n'étant pas toujours le même alors que c'est lui qui impactait fortement le framerate. A certains moment la GTX 970 n'était qu'à 6 fps de moyenne sur les 20 secondes de test, mais à 13 fps la fois suivante par exemple... alors que sur la GTX 980 nous étions à 13 fps également au premier essai, mais avons pu atteindre 22 fps lors d'une autre tentative sans aucune saccade, avant de retomber à 15 fps moyen avec saccades lors d'une autre tentative.
Etant dans un cas limite de débord VRAM avec des résultats peu concluants et très variables sur les deux cartes, mais tout de même en moyenne en défaveur de la 970, nous ne pouvons pas faire de lien évident avec le partitionnement de la mémoire et les 512 Mo plus lent. Il faut par contre noter que la consommation VRAM dès le bureau Windows est plus élevée sur la 970 : 241 Mo contre 191 Mo pour la 980, ce qui peut avoir un impact dans ce genre de cas. Il est possible que cet écart soit lié au partitionnement, ce qui donnerait ce genre de cas de manière indirecte, il serait donc intéressant de savoir d'où vient cette perte sèche de 50 Mo utiles sur la 970.
C’est ensuite sous Ryse : Son Of Rome que nous avons remarqué un écart dans des réglages très élevés, tout à fond en 2560*1440 avec sur-échantillonnage 2x2 (soit 5120*2880 pixels !). Si en mono GPU on ne note pas de différence de comportement, il faut dire que ce n’est pas très fluide avec un framerate de l’ordre de 12 à 16 fps, en SLI par contre les 980 présentent moins de saccades que les 970 (l’allocation VRAM est respectivement de 3700 et 4000 Mo environ). Attention pour autant les 980 ne sont pas épargnées par celles-ci et au-delà du framerate assez bas cela fait que le jeu n’est pas jouable dans ces conditions sur l’une ou l’autre des deux solutions. En moyenne sur 30 secondes nous arrivons à 16.9 à 21.6 fps selon les essais sur le SLI de 970, contre 27 à 29,1 fps sur le SLI de 980, un écart plus grand qu’à la normale. En passant en sur-échantillonnage 1.5x1.5 l’écart et le comportement entre les deux SLI redevient plus cohérent, avec 44 fps sur le SLI de 970 et 50 fps sur le SLI de 980 (allocation de 3500 et 3950 Mo environ).
Il est cette fois probable que l’écart en 2x2 soit lié à la gestion particulière de la mémoire sur 970, même si il n’apparait qu’en SLI. On notera toutefois que cela intervient dans des réglages qui n’offrent dans tous les cas pas un framerate moyen et un cadencement suffisants pour être jouable, même sur SLI de 980. Au passage il faut signaler que Ryse : Son Of Rome a un comportement assez étrange sur la scène de test (début de l’acte 6) au-dessus de 30 fps, peut-être des reste du portage console, et qu’il n’apprécie pas du tout l’Hyperthreading.
Pour autant, ce n'est bien entendu pas parce que nous n'avons pas trouvé aujourd'hui de cas réellement problématiques en pratique qu'ils n'existent pas, ou qu'ils n'existeront pas dans le futur, par exemple en 4K et en SLI, même si Nvidia assure qu'il travaillera sur ces pilotes dans les cas où les mécanismes automatiques n'offriraient pas de bons résultats.
Qu'en penser ? Retourner sa GTX 970 ?
La première question à se poser est de savoir comment les utilisateurs actuels de la GeForce GTX 970 doivent prendre cette nouvelle. Tout d'abord rappelons si cela est nécessaire qu'il n'y a pas de bug, la GeForce GTX 970 fonctionne bien comme prévu par les ingénieurs de Nvidia.
Par contre, nous estimons que la GeForce GTX 970 doit maintenant être vue comme une carte graphique 224-bit avec une bande passante mémoire réduite et bien sûr qui se contente de 56 ROP. Les spécifications changent, et si les ROP n'ont jamais été mis en avant publiquement par Nvidia, c'est à l'inverse le cas de la bande passante qui est encore affichée ce jour ici et là comme identique à celle de la GTX 980 et de son bus 256-bit. De quoi pouvoir parler de défaut de conformité ? Si sur le papier la bande passante peut-être là dans certains cas, en pratique la façon dont la mémoire de la GTX 970 est exploitée démontre que Nvidia lui-même estime que la bande passante n'est pas supérieure à celle d'un bus 224-bit.

Bien entendu si les spécifications changent, ce n'est pas le cas de ses bonnes performances puisque ce déficit était déjà inclus dans les résultats initiaux. C'est avant tout un problème de communication plus que de qualité du produit qui ressort aujourd'hui et il fait malheureusement qu'un utilisateur peut avoir avec raison le sentiment qu'il y a eu tromperie sur la marchandise. De notre côté, nous regrettons évidemment de ne pas avoir pu détecter ce problème afin de vous communiquer une information correcte dès le départ.
Pour ce qui est de disposer de deux partitions mémoire avec des débits hétérogènes, nous n'avons pas encore pu observer de cas où cela pose de réel problème de performances en dehors de tests synthétiques orientés à cet effet ou de réglages très gourmands dans des jeux n'offrant pas non plus des résultats satisfaisants sur 980, mais il n'est pas impossible que de telles situations existent ou existeront. Si nécessaire, Nvidia pourra dans certains cas améliorer le comportement des GTX 970 via de nouveaux pilotes. Il vaut mieux 3.5 Go + 0.5 Go que 3.5 Go "tout court", mais une GTX 970 ne pourra jamais exploiter aussi bien la totalité de ses 4 Go qu'une GTX 980.
La GTX 970 reste selon nous une excellente carte graphique, que nous vous recommandons toujours. Nul doute que cette erreur risque par contre de coûter cher en termes de réputation à cette GeForce et que Nvidia doit aujourd'hui s'en mordre les doigts. Il nous est impossible de savoir si Nvidia est de bonne foi et d'être certain qu'il s'agit au départ d'une erreur. Mais prendre volontairement un tel risque aurait été en tout cas un manque de clairvoyance évident. AMD profite bien entendu de l'aubaine pour mettre en avant ses solutions, avec des Radeon R9 290 qui sont très bien placées du fait d'une hausse de leur prix bien moins rapide que celles des GTX 970 suite à l'évolution du taux de change €/$, les revendeurs bénéficiant actuellement d'une promotion temporaire d'AMD.
Dans tous les cas, nous estimons par contre qu'un utilisateur peut se sentir lésé et que cette erreur dans les spécifications initiales est suffisante pour exiger un retour du produit auprès de son revendeur… Reste à voir si ceux-ci les accepterons et si Nvidia assumera son erreur jusqu'au bout ! Nous attendons toujours une communication officielle à ce niveau… et nous avons de plus en plus l'impression qu'il n'y en aura pas mais que Nvidia fera en coulisses en sorte de mettre de l'huile dans les rouages pour résoudre les cas problématiques entre utilisateurs insistants, revendeurs et fabricants.




Contenus relatifs
- [+] 08/03: GDC: Nvidia parle du Tile Caching d...
- [+] 12/09: La class-action GTX 970 ouverte aux...
- [+] 01/08: Tile rendering pour Maxwell et Pasc...
- [+] 30/07: 30$ pour les acheteurs de GTX 970 ?
- [+] 17/06: Baisses AMD et Nvidia pour vider le...
- [+] 24/03: GDC: VR: Nvidia Multi-Res Shading e...
- [+] 23/03: GDC: Async Compute : ce qu'en dit N...
- [+] 13/01: CES: Gigabyte passe ses GTX 900 en ...
- [+] 07/01: Rise of the Tomb Raider offert par ...
- [+] 06/10: Nouveau bundle Nvidia: Assassin's C...